
人工智能通识实践正式发布,欢迎大家体验!为支持广大院校的大数据和人工智能实训教学,需要使用平台的老师请尽快与我们联系,便于我们提前准备云服务器等资源。联系电话和微信:136-9329-0406
人工智能是通过计算机系统模拟、延伸和扩展人类智能的一类技术,其核心目标是使机器具备感知、学习、推理、决策和交互等能力,目前已渗透应用至医疗、金融、教育、交通等社会各领域,推动效率提升与社会发展。 本项目从机器学习与深度学习的基础出发,实践人工智能在自然语言处理与计算机视觉方面的应用,最后落脚于大语言模型与强化学习这两个新兴技术上。通过本项目的实训,大家可以对人工智能技术有一个基本了解,并且掌握sklearn与pytorch的实际应用。
pandas;matplotlib;seaborn;sklearn;torch;torchviz;IPython;torchvision;numpy;pillow;tqdm;time;gymnasium;re;transformers;openai
本实训从六个项目出发,了解人工智能领域的基本应用。项目共分为六章。
第一章对titanic数据集进行探究,首先确定特征变量和目标变量,然后通过缺失值处理、类别特征编码、数据归一化等操作进行数据预处理,最后分别构建logistic模型和决策树模型进行titanic生还者预测。
第二章以MNIST手写数字识别项目为例,介绍深度学习的一些基本概念以及pytorch的使用,包括如何定义模型,预处理数据,以及训练模型。
第三章在了解卷积和CNN架构的基础上搭建一个简单的CNN模型,接着基于目标检测中的经典数据集——COCO数据集构建颜色映射字典,并加载Mask R-CNN预训练模型,最后通过图像转化为张量输入模型中成功实现了目标检测。
第四章的目标是使用pytorch框架对IMDB评论数据集进行文本情感分析。在此过程中,学习文本数据的处理(清洗,编码),预训练词向量的使用,以及RNN模型的搭建和训练。
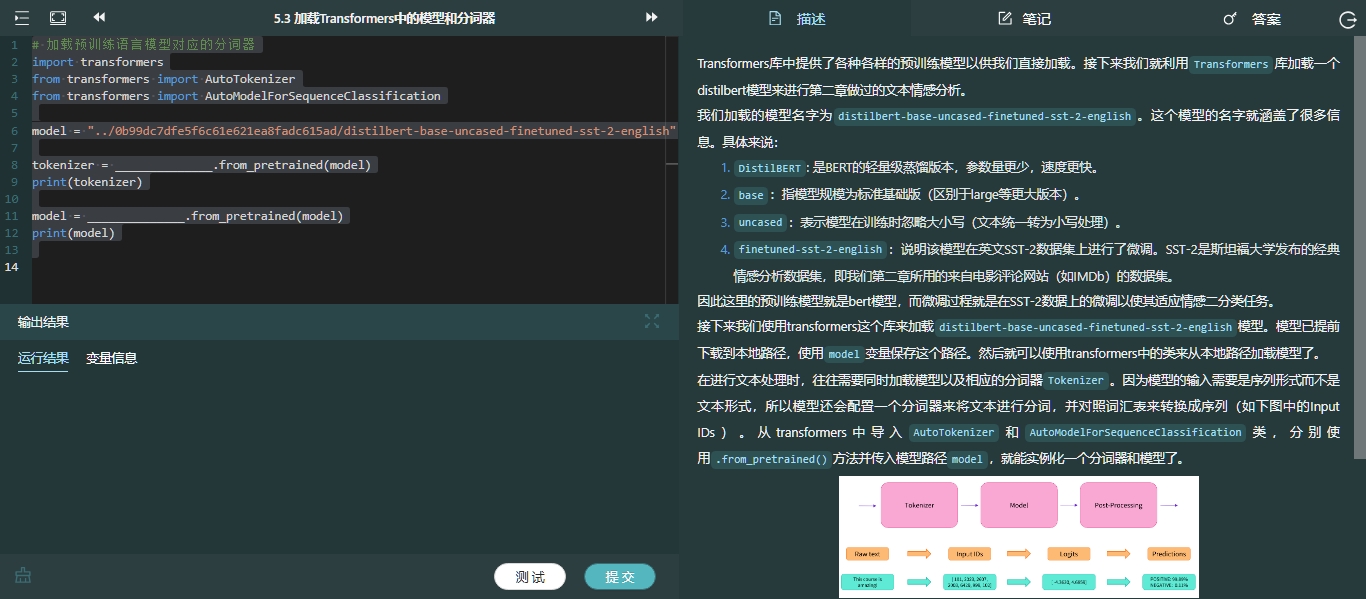
第五章首先介绍了语言模型的发展历程。然后介绍了目前大多数预训练语言模型的基础——Transformer架构。然后学习用transformers加载预训练模型完成特定的任务。最后介绍了调用大语言模型的API和提示词工程来完成某些任务。
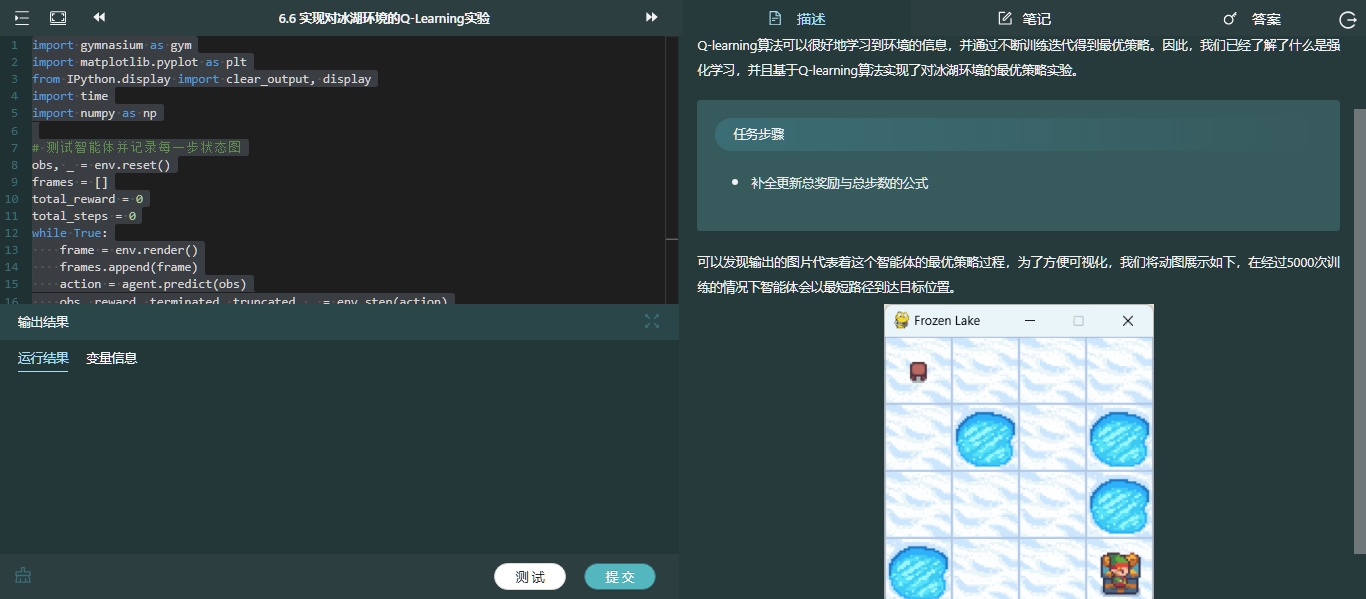
第六章首先了解强化学习与马尔可夫决策过程,接着创建该实验中的冰湖环境,构建基于Q-learning算法的模型,最后通过模拟智能体的方式实现了对冰湖环境的Q-learning实验,得到了强化学习下的最优策略。

.png)












 公司公众号
公司公众号 数据科学人工智能
数据科学人工智能 Chat
Chat